MaNIS
The Mammal Networked Information System
Introduction (Barbara Stein)
The focus of the meeting was to provide an update of MaNIS activities, particularly
with respect to georeferencing, and to demonstrate a functioning MaNIS network.
Time permitting, we also wanted to demonstrate the next generation of georeferencing
tools.
There has been tremendous interest in our georeferencing activities and progress, both nationally and internationally. Some individuals are interested in just the coordinate data associated with our georeferenced localities, apart from the related specimen records. Others have enquired about our success in facilitating collaborative georeferencing. Several consortia have expressed interested in using the MaNIS network as a model for their own institutions and, on a more global scale, there is interest in creating a network of networks like MaNIS.
Although the official start date for MaNIS was September 1, 2001, the first annual report to NSF was due July 1st (and has been submitted). I am pleased to report that we have made considerable progress over the past nine months. Although some institutions took longer than others to get started, everyone is now georeferencing and we are on target to meet the deadlines and deliverables promised at the end of the first year. In addition, I believe that our contributions to the biodiversity informatics community have been much more profound than any of us anticipated when we undertook this venture.
Presentation (John Wieczorek)
A week prior to the ASM meeting, John was an invited participant
in the Scientific and Technical Advisory Group meeting of the
GBIF
Digitization of Natural History Collection Data Subcommittee (DIGIT).
GBIF has interest in leveraging the technology and tools being
developed for the MaNIS project to create a standard protocol for biodiversity
data exchange. To that end, John was invited to give a presentation
1 on MaNIS and DiGIR (Distributed Generic Information Retrieval) at the GBIF Data
Access and Database Interoperability Subcommittee (DADI) meeting at the San Diego
Supercomputer Center on 27 June. A number of groups interested in distributed networks
of biodiversity information are anticipating the open source development of the various
software components of DiGIR which were demonstrated at the ASM meeting.
Georeferencing rates and practices
To date, approximately 108,000 out of 283,000 unique localities have been downloaded from
the MaNIS gazetteer for georeferencing. Of those, 42,000 localities already contained
coordinate data. This puts us on target for completing georeferencing of all localities
within the three-year time frame allotted. However, we have only just begun georeferencing
non-US localities, and we do not yet know to what extent we can improve on the
georeferencing rates for these localities as stated in the proposal. To be sure, many of
the more difficult localities are among the ones that remain to be georeferenced.
"Best practices" for georeferencing locality data were not put forth at the outset of the project because we did not feel we were in the position to dictate which tools each institution should use to accomplish this task. However, most institutions seem to be using the same suite of software (i.e., Access, Excel, and/or ArcView) and, given this uniformity, John offered several tips and tricks for increasing the rate and ease of georeferencing. They are as follow:
We did promise to georeference all the localities in our combined databases. What are the implications of this promise? Most individuals have started georeferencing localities from states, regions or foreign countries that are abundantly represented in their own institutions. When these localities are finished, there will remain localities that may be of less relative interest. These localities must be georeferenced as well. Therefore, altruism will have to kick in to make sure that all localities get georeferenced and no institutions are left "holding the bag."
A question was raised about determining errors for foreign localities if you do not know the extent of the nearest named place. For instance, you may know that you were 4.6km NW of Hotezel, South Africa, but if you do not know the extent of the village of Hotezel itself, how do you determine the extent of that locality?
This is a tricky problem to which there are numerous possible solutions. An ideal solution is one that is simple to remember and simple to implement and, thus, can be executed consistently under all circumstances. The first thing to remember is that we have no dictum saying that the maximum error distance has to be as small as possible. Instead, it has to be as large as necessary to ensure that we are not over-representing the accuracy of the data. With that in mind, John recommended the following approach to determining the extent of a named place when it cannot be determined directly from the maps, gazetteers, or any of the other tools at hand.
Life after the gazetteer
The current gazetteer from which you download localities is a static structure and
represents the state of your databases approximately one year ago. Once the MaNIS network
is fully functional and georeferencing is complete, the network will become a dynamic
gazetteer and replace the current structure. How will this happen?
Once georeferencing is complete, John will check for spurious data (i.e., he will check that the data fit the rules for the fields in which they have been placed) and he will put all coordinate data back into the gazetteer. He will not check the validity of the coordinates you have assigned. However, tools to visualize locality data for verification are being developed.
Having expended a tremendous amount of effort to georeference all of these localities, we are assuming that you will take advantage of this added value and put these data back into your databases. This raises two issues. First, will your current database structures accommodate the data? Second, what do you wish to do in the future with respect to new accessions and georeferencing new localities?
As to the first issue, adding data structures to your databases is relatively easy, and John is willing to do that for you at the same time he brings your institution onto the network. However, your commitment to georeferencing all future localities will require that you modify one or more of your existing data entry and report screens to accommodate the new data fields. This is not in the scope of the MaNIS project and John will not do this for you.
NOTE: It is imperative that you tell John as soon as possible if you have changed your current database management software, or if you are planning to change it within the next two years (i.e., you either plan to upgrade it or replace it with an entirely new system). Changes of this nature will affect when your institution will be to be connected to the network.
The MaNIS network
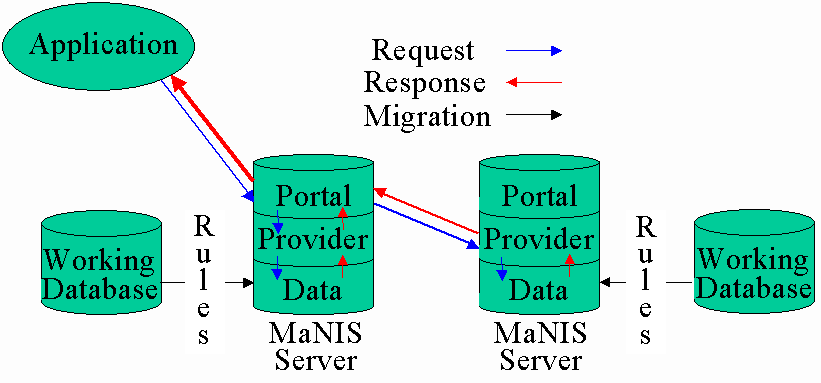
When we talk about the MaNIS network there are two main concepts to understand - the
physical network, composed of computers linked to the internet, and the data network,
composed of the specimen data and the software that will allow you to retrieve those data
over the physical network. Below is a schematic of MaNIS that combines these two
concepts:
In the diagram above, each "Working Database" is an institution's current in-house database. "Rules" set by the institution will affect data migration to that institution's MaNIS server (e.g., how frequently the data are migrated, whether locality data on endangered species will be displayed).
The "Application" shown in the diagram denotes any interface that might make a query of the MaNIS network. The application sends the request to a "Portal," which is a software application that knows how to discover providers, formulate queries that the providers will understand, and send requests for data to them. In turn, the "Provider" is a software application that runs independently on each MaNIS server and waits for requests for data to come in. When a request arrives, the providers translate the request and send it to their local data repository (labeled as "Data" on each MaNIS server in the diagram above). Each provider then assembles the data returned by its repository into a response, sends the response back to the portal, and logs information about the request and the response in an archive. The portal then assembles all of the responses from all of the providers into a single result set, which it passes back to the application that first made the request.
Although only one portal is required to get data from all of the providers on a network (and it does not even have to be on a MaNIS server), every MaNIS server will have its own portal, in addition to a provider, a web server, and data resources that have been migrated from the local working database with local rules in place. This redundancy will not only assure that a MaNIS portal will always be available, but it will also allow each institution to incorporate MaNIS into their existing suite of web services. For institutions without existing web services, the local portal can become the basis for such services.
Below is a screen shot of the first implementation of the MaNIS search form. Because this is simply a prototype to test functionality of the network, we did not consult the project participants on the design of this page. We are happy to solicit input once the more technical issues have been ironed out, but what you see below provides a good starting point for development and testing of the MaNIS network.
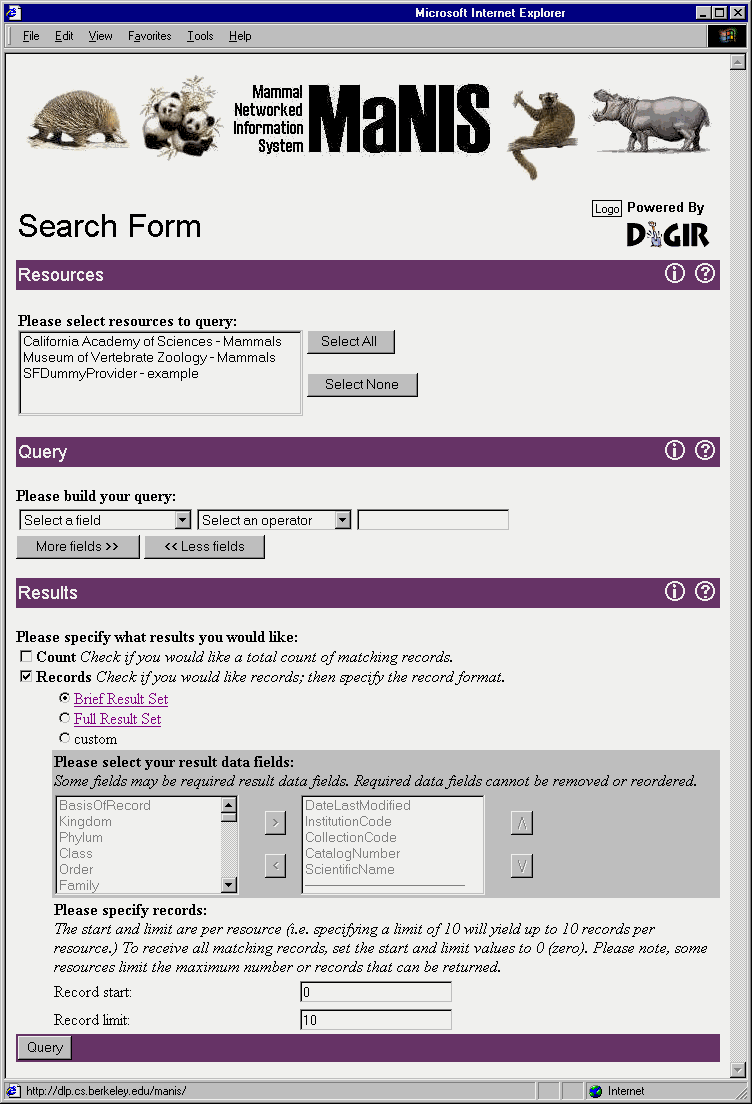
The first thing you will notice on the right-hand side beneath the network banner is that the site is "Powered by DiGIR." DiGIR (Distributed Generic Information Retrieval) is an open source software development project specifically designed to allow distributed queries against resources that can be discovered dynamically. DiGIR consists of provider software, portal software, and a protocol specification for communication between the two. You may recall from our NSF proposal that we said we would base the MaNIS network on the Z39.50 protocol. However, after writing the proposal, it became clear that there are several advantages to using XML (eXtensible Markup Language) to package requests and responses and to pass these over the Internet using HTTP (Hyper-Text Transfer Protocol). Among the advantages over Z39.50 are 1) the ability to avoid firewall issues, and 2) the decoupling of the portal and provider software, allowing greater overall flexibility in the system. A brief history of the development of DiGIR has been posted on the MaNIS Events web page.
The next thing you will notice are the institutions listed in the first dialog box. At the ASM meeting there were only two institutions on the network, California Academy of Sciences and Museum of Vertebrate Zoology. As of this writing, there are three as University of Alaska Museum was added in the week following the ASM demo. (The screen shot actually shows something different because it was made following the meeting while development and testing of DiGIR continue.)
John did several MaNIS queries for the group and, as promised, combined results were returned from both CAS and MVZ. In addition to the output that was shown at the meetings, options to download the data as tab-delimited text or as XML have since been added to the user interface. In addition, the ability to get a count of the matching records has been added.
As expected, the demo generated quite a bit of discussion and positive feedback. Barbara then raised the next topic to the group...
At what point do we have a network that can be made public?
It is anticipated that John will have the first 5-6 institutions online by September, which
is exactly what we said we would have done by the end of our first year of funding. Those
first institutions are ones that he can connect while still in Berkeley, either because he
has direct access to those institutions' databases or those institutions have in-house IT
support to assist him. In addition, these first participants will represent the range of
database variation with which he will have to contend in order to bring the remaining
museums online. Proceeding in this way will allow John to work out all the issues he is
likely to confront in dealing with the remaining institutions.
The group was then asked when they would be ready to have the network be publicly accessible. The general sentiments were that 1) the demand for the network clearly exists, 2) making our data available sooner rather than later would heighten visibility of both the project and it's participants, and 3) public access would help us to identify desired or needed modifications to the system while there is still quite a bit of time and money left to implement them. No real disadvantages to going public within the next year were identified other than the fact that those who were not first on the network might feel left behind.
The general consensus of the group was that they would like to see the network go public after the first 5-6 institutions are online and the system has been thoroughly tested and debugged. It was then suggested that a dialog box be added in a prominent position that would list the names of all MaNIS participants and indicate that they would be brought online in turn. This might be done in addition to a footer on the portal home page that listed all the participants and credits NSF for funding the development of MaNIS.
John then asked each institution to consider what, if any, "rules" they will wish to have implemented as part of their migration scripts. The MVZ has no rules in place and makes all of its specimen data available on its web site and in MaNIS. However, an example of a rule that might be implemented is the suppression of specific locality data for endangered species. It was then suggested that the portal home page have the contact information for each institution in case the user desires additional data or information. This feature has since been implemented.
Miscellaneous issues
Before concluding the formal part of the meeting, Barbara reminded the group that NSF had
funded a workshop which is to take place at next year's ASM meeting. The purposes of that
workshop are to 1) demonstrate the capabilities of the MaNIS network, 2) answer questions
regarding its implementation, and 3) foster additional participation within the mammal
community in data sharing. The timing and location of the workshop are fortuitous in that
the SPNHC meetings will be held at Texas Tech University the week immediately preceding the
ASM meeting. It is hoped that a number of individuals attending SPNHC will opt to stay an
extra day or two to attend our presentation. Robert Baker, Chair of the TTU local
committee, has kindly agreed to host our workshop on the first day of the ASM meetings to
facilitate attendance by SPNHC members. The MaNIS group then agreed that they would like
to hold our regular ASM meeting in Lubbock, in addition to the formal workshop. Hence, we
will plan accordingly for that.
Another issue to be aware of is the specification of the federation schema that will describe the data attributes that will be searchable and returnable in the MaNIS network. There is ongoing discussion of the Darwin Core version 2, which is an extension of the Darwin Core (Note: the Darwin Core page doesn't open correctly in Netscape 4.73 on PCs) used in the Species Analyst project. As a group, the participants in MaNIS need to come to a consensus about the range of questions that the network must support and the details of the data that must be accessible. All MaNIS participants are invited to review the Darwin Core version 2 draft specification and make comments on the mammal-z-net list.
After the formal session ended
Those needing to leave at 5:00pm did so. For those who remained, John previewed the next
generation of automated georeferencing tools. Developed in collaboration with Reed Beaman
at the University of Kansas Biodiversity Research Center, the new tool has the potential to
increase georeferencing rates by an order of magnitude. It would also work on foreign
localities. John released the URL for the site to the listserv following the meetings,
with the caveat that the tool is still in development and can be tried, but results should
not be incorporated into your data files. Detailed documentation is needed to
understand the assumptions involved in generating the result set.
1 An archive of the webcast for the presentations at the GBIF DADI meeting
can be found at the following URL:
http://chipotle.speciesanalyst.net/dadi/ow.asp?WebcastArchives
The presentation for MaNIS is the last one before lunch on 27 June
2002.
2 The manisgeoreftemplate.mdb file has been updated. This new version has two queries in it, one to find out which localities have not yet been georeferenced, and another by which to group localities from the same named place.
| John Wieczorek, 19 Jul 2002 |
Rev. 24 Feb 2008, JRW
|